

수수종자는 아프리카, 아시아를 포함한 반건조 열대 지역 에서 에너지원과 단백질원을 공급하는 주요 식량자원으로 이용되고 있으며(Belton & Taylor, 2004), 우리나라에서는 전통적으로 혼반용 또는 떡 등의 식량보조 식품으로 이용되 고 있다. 또한 최근에 수수의 건강 보조 및 증진 효과에 대 한 연구가 활발하게 진행되면서, 성인병의 대표적인 만성질 환인 당뇨, 및 노화에 대한 억제 효과가 우수하다는 결과가 보고되고 있다(Jeon et al., 2011; et al., 2009; Seo et al., 2011). 수수 종자에 함유된 주요한 건강 증진 물질로는 페놀 화합물 등의 식물체 이차 대사물질이 확인되고 있다(Dykes & Rooney, 2006).
혈당강하 관련 최근 국내 연구에서, 혈당강하 및 항산화 효과가 우수한 수수 ‘밀양 3호’가 개발되었으며, 수수 추출물 유래 fatty acid amides가 탄수화물 가수분해효소(α-amylase 와 α-glucosidase)에 대한 억제 효능이 우수하다고 보고되었 다(RDA, 2013). 또한 수수 추출물은 당뇨 동물모델에서 혈 당 및 콜레스테롤 강하 효과가 있었으며, 이는 pAMPK/AMPK ratio 증가, PEPCK와 phosphor-p38/p38 ratio 감소, PPARgamma의 발현을 통해 인슐린민감성을 개선 기전을 보고하 였다(Park et al., 2012).
식물 유래 항당뇨와 관련하여 amaranth의 종자 단백질 glutelin (Silva-Sanchez et al., 2008)과 콩 종실에 leginsulin (cysteinerich peptides)가 혈당조절 기작에 관여한다고 최근에 보고 되었지만(Kim et al., 2012), 수수 종자 단백질에 대한 연구 보고는 없다. 수수종자 단백질의 인체 건강 증진 효과에 대 한 연구 결과로는 프롤라민 단백질의 키모트립신 분해 수화 물이 혈압 저하 효과(Kamath et al., 2007)와 수수 종자에서 추출한 펩타이드 및 단백질이 항균 및 항바이러스 효과를 보고되었다(Camargo Filho et al., 2008; Mincoff et al., 2006). 작물 종자에서 유래된 펩타이드가 의학, 제약 및 식품학 계에서 건강 기능성 요인(기능성 펩타이드, bioactive peptides) 으로 밝혀지고 있으며(Farrokhi et al., 2008; Hartmann & Meisel, 2007), 기능성 펩타이드를 유발하는 식물 공급원은 밀, 콩, 옥수수, 벼, 버섯, 호박 및 수수 등으로 매우 다양한 작물의 종자에서 유래되고 있음이 보고되고 있어(Ng, 2004; Sarmadi & Ismail, 2010), 수수종자 단백질 및 펩타이드의 인체 건강 증진에 기능성 역할을 시사하고 있다.
SELDI-TOF MS (surface enhanced laser desorption/ionization time of flight mass spectrometry)은 단백질 칩을 이용하여 펩타이드를 검출하고 정량화하는 질량분석기술이다. 단백 질 칩 표면의 크로마토그래픽의 화학적 물질분리 기능을 부여 함으로써, 특별한 물질 분리과정 없이 추출된 조시료(crude sample)의 화학적 특성에 따라 칩 표면에서 직접 분리하고 바로 질량분석을 하기 때문에 단시간에 대량의 시료를 분석 하는 high-throughput 프로테옴 방법으로 적용되고 있다. 하 지만 질량분석의 범위가 30 kDa 이하의 저분자 단백질에 제 한이 되며, 검출된 펩타이드를 동정하지 못하는 단점이 있지 만, top-down 방식의 펩타이드 프로파일링과 펩타이드 양 적 발현 비교가 가능하다(Issaq et al., 2002; Ndao et al., 2010). SELDI-TOF MS 기술의 적용은 각종 암을 포함한 다양한 질병의 조기 진단을 위한 혈청 및 혈장 단백질의 펩 타이드 프로파일링 및 바이오 마커 개발(Ndao et al., 2010; Petricoin & Liotta, 2004)로 시작되었다. 식물 연구에서 Phytic acid 함량이 낮은 쌀 계통에서 Phytic acid 연관 펩타이드 마커(8,642 Da) (Emami et al., 2010)와 포도 품종 식별을 위한 바이오마커가 SELDI-TOF MS 기법을 적용하여 보고 되었다(Povero et al., 2010). 국내 연구로서는 SELDI-TOF MS를 이용한 벼 종자 단백질의 펩타이드 분석으로 근연 관 계가 가까운 일품벼, 고아미2호, 고아미 3호의 판별이 가능 하였으며, 각 품종별 바이오마커를 선발하였으며(Park et al., 2013), 수수종자의 펩타이드 프로파일링을 위한 SELDI-TOF MS 분석조건 최적화 연구가 선행되었다(Park et al., 2013).
현재까지 식물 및 종자 펩타이드의 프로파일링에 관한 연 구는 매우 미진하다. 펩타이드 프로파일링은 단백질 프로파 일링의 연구 방법적 역할과 같이 분자량이 10 kDa 이하의 저분자 단백질 즉, 펩타이드의 양적 또는 질적 형질을 특성 화 할 수 있으며, 외적 내적 환경변화 또는 식물종간 차이에 대한 펩타이드의 양적발현 양상의 변화를 측정함으로써 특 이 발현 펩타이드를 선발할 수 있다. 본 연구는 혈당강하 수 수 종자의 펩타이드를 탐색하여 특성화하고, 특이 발현 펩 타이드를 선발하기 위하여, 농촌진흥청에서 선발된 혈당강 하 수수 7품종과 대조품종 5품종에 대한 종자 펩타이드 프 로파일링을 SELDI-TOF MS 기법을 활용하여 실시하였다.
재료 및 방법
시료 및 측정장비
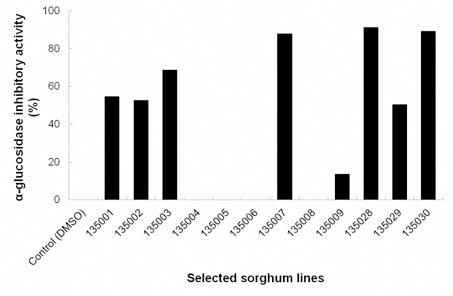
본 과제의 혈당강하 수수품종의 종자 저분자 단백질 프로 파일링 및 펩타이드 마커군 탐색에 사용된 수수 종자는 2011년 농촌진흥청에서 육성된 혈당강하 관련 육성 수수 계통 12종으로 혈당강하 수수 7계통: 135001, 135002, 135003, 135007, 135028, 135030, 135029, 및 비 혈당강하 대조구 수수 5계통 : 135004, 135005, 135006, 135008, 135009으 로 하였으며, 0.5 mm로 균일하게 마쇄하여 4°C에서 저장 한 시료를 사용하였다(Fig. 1). 단백질 함량 측정에는 UVSpectrophotomater (MECASYS, Korea)를 사용하였고, 펩 타이드 분석에는 SELDI-TOF MS (BIO-RAD, USA)을 사 용하였다.
단백질 추출 및 단백질 정량
총 단백질 추출은 미세하게 마쇄한 잡곡 종자 0.1 g에 12.5 mM sodium borate, pH 10.0 (2% β-ME, 1% triton X-100) 1 ml를 넣은 후 4°C에서 180 rpm으로 1시간동안 흔 들고, 4°C에서 12,000 x g로 10분 동안 원심분리하여 상등 액을 falcon tube에 옮겨 담는 과정을 3회 반복하여 얻었다 (Hamaker et al., 1995; Park & Bean, 2003; Park et al., 2013). 총 단백질 함량은 Bradford 분석법을 적용하였다(Bradford, 1976). 단백질 추출액은 펩타이드 프로파일링을 위한 SELDI-TOF MS에 즉시 분석되었다. SELDI-TOF MS 분석의 반복은 단 백질 추출 6반복을 두어 실시하였다.
수수종자 펩타이드 프로파일링
펩타이드 분석시료 전처리
수수종자 펩타이드 프로파일링의 분석은 Park et al. (2013) 의 방법에 따라 실시되었다. 수수 종자 단백질 추출 시료를 시료 바인딩 버퍼에 20배 희석한 후 4°C에 보관한다. 단백 질 칩의 최적화를 위하여 시료 바인딩 버퍼를 200 ul를 취 하여 well에 첨가하여 실온에서 250 rpm으로 5분 교반 후 바인딩 버퍼를 제거하였다. 위와 같은 방법으로 1회 반복을 하였다. 바인딩 버퍼가 제거된 단백질 칩에 희석된 단백질 시료를 150 ul 취하여 well에 첨가하여 실온에서 30분간 250 rpm으로 교반하였다. 단백질 칩에 결합이 안 된 단백질의 세정은 바인딩 버퍼 200 ul를 취하여 well에 첨가하여 실온 에서 5분간 250 rpm으로 흔들어 실시하였다. 이와 같은 방 법을 2회 반복하였다. HPLC용 증류수로 2회 세정 과정을 반복하여 남아있던 바인딩 버퍼를 제거하였다. 단백질 칩을 완전히 건조시킨 후 EAM를 1 ul씩 첨가하여 결정체를 형 성하도록 하였다. EAM 첨가를 1회 더 반복하였다. EAM은 1~15 kD를 분석에 용이한 CHCA (alpha-cyano-4-hydroxycinnamic acid)를 50% CHCA EAM solution (50% ACN, 0.25% TFA)으로 용해하여 실온에서 10,000 rpm으로 10분 간 원심분리 하여 상등액을 사용하였다. 최종적으로 EAM 이 첨가된 단백질 칩을 완전히 건조시킨 후 SELDI-TOF MS 분석을 실시하였다.
Data 선택
All-in-One peptide standard를 이용하여 질량을 보정하였 다. TOF 스펙트럼은 focus mass 5,000 Da, Matrix attenuation 1,000 Da, sample rate 800 MHz으로 low mass protein protocol 을 이용하여 생성하였다. 레이저 에너지의 설정은 EAM-CHCA 로 최적화하여 2,500 nJ을 조사하였다. Peak의 검출과 군집 분석은 ProteinChip Data manager를 이용하였다. 분자량 1,000 Da이하의 peak는 EAM에 의해 다른 화학적 물질로 오염이 되어 제거하였다. 스펙트럼는 1,000 Da에서 30,000 Da로 표 준화하였다. Peak 검출에서 first-pass peak 검출은 S/N의 비 율을 5, valley depth는 3으로 설정하였고, second-pass peak 의 검출은 S/N의 비율을 2, valley depth는 2의 신호로 설정 하였다. Estimated peak는 At cluster center로 설정하였다.
결과 및 고찰
수수 종자의 펩타이드 프로파일링
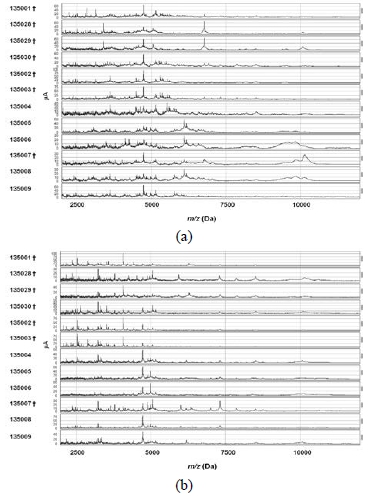
농촌진흥청에서 육성된 혈당 강하 수수 7계통과 비 혈당 강 하 5계통 종자의 펨타이드 스펙트럼을 SELDI-TOF MS의 CM10 (weak cation exchanger)와 Q10 (strong anion exchanger) protein chip array을 활용하여 측정하였다(Fig. 1). CM10과 Q10 에서 분자량 10 kDa 이하의 수수 종자에서 검출된 펩 타이드 피크 스펙트럼은 수수 12계통에서 각각 다르게 나 타나, 계통 간 종자에서 유래되는 펩타이드의 양적 또는 질 적 발현에 차이가 있음을 제시하였다. 종자 펩타이드의 발 현이 품종 간 차이가 있다는 연구결과는 SELDI-TOF MS 기법을 활용한 쌀 품종비교에서 보고되었으며, 품종별 특이 적으로 발현하는 10 kDa 이하의 펩타이드가 품종 식별의 바이오마커로 선정되었다(Park et al., 2013). 분자량 10 kDa 이하의 펩타이드의 양적발현은 겔 기반 전기영동 기법으로 는 측정하기는 쉽지 않지만, SELDI-TOF MS 기법은 20 kDa 이하의 저분자 단백질을 검출하는데 큰 장점을 갖고 있어 (Issaq et al., 2002), 종자 및 식물체 유래 펩타이드의 양적 또는 질적 발현 및 탐색에 유효하게 적용될 것으로 사료된다.
수수 12계통 종자에서 검출된 펩타이드 피크의 종류(peak cluster), 질량(M/Z) 및 양적발현 정도(peak intensity)는 Table 1과 Table 2에 있다. 분자량의 범위가 2~20 kDa에서 검출된 수수 12계통 종자의 펩타이드는 CM10에서 104개 (Table 1)와 Q10 에서 95개였다(Table 2). 펩타이드 양적발 현에서 12계통 간 유의성(p < 0.01)을 보인 펩타이드는 CM10 에서 99개와 Q10에서 93개로 나타나, 20 kDa이하에서 검 출된 대부분의 펩타이드가 계통 간 양적 차이를 나타내었다 (Table 1과 2에서 굵은체로 된 피크 클러스터). 이러한 결과 는 수수 각 계통 종자에서 유래되는 특이적인 펩타이드가 존 재하며, 고유한 펩타이드 프로파일이 있음을 제시하고 있다. (Fig. 2)
Table 1.
Peptide peak cluster deteced on CM10 array on the mass range from 2 to 20 kDa in twelve sorghum lines (continue).
| Peak cluster | p-value | M/Z‡ | Intensity | Peak cluster | p-value | M/Z‡ | Intensity | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | CV (%) | mean | CV (%) | mean | CV (%) | mean | CV (%) | ||||
| 1 | 0.000075 | 2030.86 | 0.05 | 12.9 | 59.4 | 40 | 0.000008 | 5059.68 | 0.18 | 11.5 | 79.5 |
| 2 | 0.001355 | 2116.79 | 0.08 | 7.0 | 176.4 | 41 | 0.000015 | 5104.65 | 0.06 | 16.5 | 46.9 |
| 3 | 0.000000 | 2231.53 | 0.02 | 11.5 | 70.9 | 42 | 0.000016 | 5146.82 | 0.03 | 25.2 | 49.5 |
| 4 | 0.000720 | 2247.92 | 0.06 | 10.4 | 47.1 | 43 | 0.000000 | 5167.72 | 0.04 | 15.1 | 49.4 |
| 5 | 0.008853 | 2373.00 | 0.14 | 13.7 | 60.4 | 44 | 0.000000 | 5253.43 | 0.07 | 5.6 | 129.6 |
| 6 | 0.000032 | 2453.52 | 0.03 | 16.3 | 57.3 | 45 | 0.000000 | 5296.01 | 0.02 | 13.6 | 124.6 |
| 7 | 0.000028 | 2502.27 | 0.06 | 11.2 | 65.6 | 46 | 0.000000 | 5319.18 | 0.03 | 9.9 | 103.5 |
| 8 | 0.000000 | 2520.07 | 0.02 | 10.3 | 84.8 | 47 | 0.000000 | 5335.33 | 0.04 | 9.0 | 94.7 |
| 9 | 0.000008 | 2795.06 | 0.11 | 8.3 | 111.9 | 48 | 0.000000 | 5373.00 | 0.04 | 10.9 | 123.5 |
| 10 | 0.000000 | 2845.37 | 0.02 | 10.1 | 102.9 | 49 | 0.000000 | 5393.64 | 0.01 | 8.5 | 110.4 |
| 11 | 0.034269 | 2889.54 | 0.14 | 11.0 | 55.3 | 50 | 0.000001 | 5458.58 | 0.09 | 8.9 | 57.0 |
| 12 | 0.000046 | 2924.84 | 0.03 | 11.1 | 58.6 | 51 | 0.000000 | 5498.82 | 0.01 | 6.7 | 87.6 |
| 13 | 0.000050 | 3047.32 | 0.20 | 7.8 | 69.1 | 52 | 0.000000 | 5519.05 | 0.02 | 7.1 | 137.9 |
| 14 | 0.000001 | 3132.89 | 0.03 | 16.5 | 61.1 | 53 | 0.000000 | 5533.25 | 0.04 | 10.2 | 110.3 |
| 15 | 0.000000 | 3155.53 | 0.13 | 10.3 | 53.8 | 54 | 0.000000 | 5552.10 | 0.07 | 6.3 | 103.7 |
| 16 | 0.000057 | 3368.20 | 0.04 | 6.7 | 105.0 | 55 | 0.000000 | 5630.26 | 0.31 | 9.9 | 86.5 |
| 17 | 0.000041 | 3397.97 | 0.10 | 13.7 | 101.8 | 56 | 0.000000 | 5769.25 | 0.14 | 9.8 | 107.9 |
| 18 | 0.000104 | 3477.07 | 0.01 | 8.7 | 53.2 | 57 | 0.000001 | 5855.08 | 0.16 | 8.3 | 81.9 |
| 19 | 0.000871 | 3496.33 | 0.03 | 9.1 | 63.8 | 58 | 0.000030 | 5905.05 | 0.29 | 5.9 | 86.2 |
| 20 | 0.000100 | 3522.81 | 0.12 | 13.6 | 40.4 | 59 | 0.000000 | 6009.90 | 0.05 | 8.1 | 81.6 |
| 21 | 0.000143 | 3583.44 | 0.12 | 7.4 | 70.7 | 60 | 0.000000 | 6046.88 | 0.05 | 6.7 | 56.9 |
| 22 | 0.000012 | 3611.09 | 0.09 | 22.8 | 66.8 | 61 | 0.000000 | 6091.55 | 0.11 | 11.5 | 102.5 |
| 23 | 0.000000 | 3677.23 | 0.10 | 12.8 | 64.5 | 62 | 0.000000 | 6121.80 | 0.03 | 8.2 | 83.0 |
| 24 | 0.043222 | 3791.46 | 0.09 | 11.9 | 34.9 | 63 | 0.000000 | 6174.39 | 0.09 | 8.0 | 101.8 |
| 25 | 0.000047 | 3953.27 | 0.08 | 6.6 | 79.9 | 64 | 0.000016 | 6377.67 | 0.38 | 5.7 | 51.2 |
| 26 | 0.024434 | 4019.57 | 0.03 | 7.5 | 40.1 | 65 | 0.000030 | 6540.03 | 0.02 | 3.0 | 57.7 |
| 27 | 0.000003 | 4112.78 | 0.27 | 15.8 | 58.4 | 66 | 0.000000 | 6590.45 | 0.08 | 5.5 | 77.0 |
| 28 | 0.001117 | 4261.92 | 0.32 | 14.3 | 46.0 | 67 | 0.000000 | 6638.20 | 0.19 | 3.2 | 103.2 |
| 29 | 0.000000 | 4434.37 | 0.15 | 8.6 | 72.5 | 68 | 0.000000 | 6773.50 | 0.20 | 14.7 | 112.1 |
| 30 | 0.000002 | 4488.83 | 0.02 | 19.8 | 59.1 | 69 | 0.000003 | 6902.26 | 0.17 | 4.8 | 80.4 |
| 31 | 0.001499 | 4514.17 | 0.08 | 11.9 | 57.9 | 70 | 0.000175 | 7043.69 | 0.36 | 5.3 | 41.9 |
| 32 | 0.000625 | 4540.14 | 0.04 | 17.5 | 30.7 | 71 | 0.000002 | 7194.89 | 0.16 | 2.6 | 79.0 |
| 33 | 0.000052 | 4581.54 | 0.11 | 15.8 | 42.9 | 72 | 0.000004 | 7317.42 | 0.12 | 4.3 | 89.0 |
| 34 | 0.000011 | 4615.88 | 0.14 | 11.8 | 55.8 | 73 | 0.000115 | 7876.93 | 0.08 | 3.7 | 96.5 |
| 35 | 0.000009 | 4732.26 | 0.04 | 42.9 | 55.9 | 74 | 0.000047 | 8002.89 | 0.36 | 3.2 | 42.3 |
| 36 | 0.000185 | 4753.50 | 0.08 | 18.0 | 35.6 | 75 | 0.000097 | 8184.17 | 0.25 | 3.8 | 40.1 |
| 37 | 0.000003 | 4834.49 | 0.12 | 14.7 | 44.4 | 76 | 0.001762 | 8401.00 | 0.25 | 2.1 | 61.6 |
| 38 | 0.000000 | 4968.00 | 0.02 | 9.8 | 77.1 | 77 | 0.014088 | 8515.84 | 0.09 | 6.0 | 58.1 |
| 39 | 0.000000 | 4993.26 | 0.14 | 12.2 | 49.2 | 78 | 0.000016 | 8814.22 | 0.50 | 0.9 | 98.0 |
| 79 | 0.000001 | 9106.29 | 0.28 | 1.5 | 100.9 | 92 | 0.000003 | 13305.97 | 0.11 | 1.1 | 90.1 |
| 80 | 0.000002 | 9414.56 | 0.11 | 4.0 | 61.4 | 93 | 0.000000 | 13462.14 | 0.18 | 1.0 | 125.4 |
| 81 | 0.000000 | 9555.34 | 0.25 | 4.8 | 69.6 | 94 | 0.000001 | 14098.34 | 0.52 | 0.7 | 119.6 |
| 82 | 0.000000 | 9848.30 | 0.08 | 4.3 | 153.9 | 95 | 0.000919 | 14583.24 | 0.10 | 0.2 | 134.4 |
| 83 | 0.000000 | 10102.62 | 0.27 | 7.1 | 101.3 | 96 | 0.003210 | 14792.68 | 0.51 | 0.2 | 74.7 |
| 84 | 0.000000 | 10212.76 | 0.34 | 4.7 | 120.9 | 97 | 0.000033 | 15443.99 | 0.58 | 0.3 | 119.4 |
| 85 | 0.001517 | 10672.91 | 0.26 | 0.7 | 86.4 | 98 | 0.000002 | 15933.44 | 0.77 | 0.4 | 84.4 |
| 86 | 0.000022 | 10951.48 | 0.34 | 0.8 | 78.6 | 99 | 0.000811 | 16443.71 | 0.36 | 0.1 | 112.5 |
| 87 | 0.000008 | 11312.26 | 0.30 | 1.3 | 99.5 | 100 | 0.107731 | 16922.98 | 0.66 | 0.2 | 64.6 |
| 88 | 0.000025 | 11627.91 | 0.04 | 0.3 | 137.5 | 101 | 0.001048 | 17385.08 | 0.09 | 0.1 | 91.6 |
| 89 | 0.000029 | 11902.15 | 0.29 | 0.4 | 84.4 | 102 | 0.000027 | 18310.02 | 0.81 | 0.3 | 82.0 |
| 90 | 0.000180 | 12321.01 | 0.50 | 0.9 | 84.6 | 103 | 0.000000 | 19140.50 | 0.26 | 1.1 | 148.1 |
| 91 | 0.000000 | 12710.79 | 0.31 | 1.2 | 77.0 | 104 | 0.000000 | 19730.03 | 0.57 | 1.9 | 154.8 |
Table 2.
Peptide peak cluster deteced on Q10 array on the mass range from 2 to 20 kDa in twelve sorghum lines.
| Peak cluster | p-value | M/Z‡ | Intensity | Peak cluster | p-value | M/Z‡ | Intensity | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | CV (%) | mean | CV (%) | mean | CV (%) | mean | CV (%) | ||||
| 1 | 0.000001 | 2083.22 | 0.09 | 11.7 | 94.3 | 21 | 0.000000 | 3129.36 | 0.02 | 4.7 | 95.0 |
| 2 | 0.000859 | 2159.43 | 0.12 | 4.5 | 65.2 | 22 | 0.000002 | 3184.31 | 0.03 | 9.6 | 58.2 |
| 3 | 0.000000 | 2181.00 | 0.03 | 13.9 | 68.6 | 23 | 0.000056 | 3250.65 | 0.02 | 29.3 | 46.9 |
| 4 | 0.005650 | 2237.37 | 0.03 | 8.3 | 49.1 | 24 | 0.000001 | 3266.87 | 0.07 | 10.2 | 46.6 |
| 5 | 0.000004 | 2350.17 | 0.02 | 8.2 | 65.1 | 25 | 0.000001 | 3286.49 | 0.04 | 6.9 | 55.0 |
| 6 | 0.000015 | 2383.76 | 0.07 | 11.5 | 66.9 | 26 | 0.000084 | 3323.10 | 0.04 | 10.1 | 37.1 |
| 7 | 0.000001 | 2401.74 | 0.02 | 6.1 | 73.0 | 27 | 0.000000 | 3339.97 | 0.02 | 19.7 | 81.1 |
| 8 | 0.000006 | 2434.96 | 0.08 | 10.9 | 55.2 | 28 | 0.000001 | 3358.46 | 0.13 | 12.9 | 51.1 |
| 9 | 0.000000 | 2489.51 | 0.02 | 5.0 | 120.8 | 29 | 0.000000 | 3520.60 | 0.03 | 15.2 | 93.5 |
| 10 | 0.000000 | 2560.57 | 0.07 | 24.2 | 88.2 | 30 | 0.000000 | 3593.91 | 0.03 | 7.8 | 84.8 |
| 11 | 0.000000 | 2593.83 | 0.02 | 10.2 | 105.9 | 31 | 0.000007 | 3669.82 | 0.09 | 7.0 | 49.0 |
| 12 | 0.000032 | 2608.78 | 0.02 | 5.6 | 65.9 | 32 | 0.000002 | 3723.74 | 0.01 | 3.3 | 129.5 |
| 13 | 0.000000 | 2645.47 | 0.03 | 9.3 | 86.3 | 33 | 0.000000 | 3808.91 | 0.02 | 10.4 | 59.7 |
| 14 | 0.000000 | 2690.62 | 0.02 | 7.7 | 74.5 | 34 | 0.000001 | 3934.91 | 0.26 | 7.4 | 28.3 |
| 15 | 0.000002 | 2747.79 | 0.02 | 5.1 | 90.0 | 35 | 0.000000 | 4078.68 | 0.01 | 33.9 | 132.8 |
| 16 | 0.000000 | 2907.95 | 0.01 | 11.5 | 113.5 | 36 | 0.000012 | 4105.50 | 0.19 | 12.5 | 107.4 |
| 17 | 0.000005 | 2934.40 | 0.22 | 9.1 | 54.6 | 37 | 0.000015 | 4148.88 | 0.11 | 4.9 | 56.0 |
| 18 | 0.019664 | 2966.74 | 0.15 | 5.5 | 75.8 | 38 | 0.000000 | 4210.70 | 0.04 | 8.1 | 78.4 |
| 19 | 0.014688 | 3018.71 | 0.11 | 5.7 | 63.0 | 39 | 0.000000 | 4226.43 | 0.04 | 8.2 | 61.7 |
| 20 | 0.000000 | 3063.57 | 0.01 | 5.6 | 106.5 | 40 | 0.000001 | 4269.50 | 0.08 | 6.6 | 56.6 |
| 41 | 0.000000 | 4423.36 | 0.04 | 7.0 | 44.2 | 69 | 0.000769 | 6712.16 | 0.07 | 1.3 | 80.6 |
| 42 | 0.000000 | 4441.31 | 0.02 | 8.9 | 107.3 | 70 | 0.000059 | 6792.84 | 0.19 | 1.1 | 108.5 |
| 43 | 0.000000 | 4457.49 | 0.02 | 5.5 | 106.0 | 71 | 0.000003 | 7005.81 | 0.11 | 3.7 | 52.1 |
| 44 | 0.000000 | 4537.12 | 0.01 | 4.7 | 80.1 | 72 | 0.000002 | 7207.54 | 0.04 | 2.2 | 52.5 |
| 45 | 0.000002 | 4603.07 | 0.02 | 4.8 | 86.1 | 73 | 0.000001 | 7318.43 | 0.07 | 9.8 | 62.8 |
| 46 | 0.000000 | 4625.82 | 0.01 | 3.7 | 91.9 | 74 | 0.000000 | 7677.72 | 0.12 | 1.0 | 100.0 |
| 47 | 0.000000 | 4679.03 | 0.01 | 5.5 | 110.3 | 75 | 0.000000 | 7870.43 | 0.03 | 3.5 | 63.2 |
| 48 | 0.000001 | 4733.66 | 0.05 | 39.3 | 65.8 | 76 | 0.000411 | 8221.25 | 0.12 | 0.9 | 65.0 |
| 49 | 0.000000 | 4747.97 | 0.02 | 15.2 | 64.8 | 77 | 0.000000 | 8400.84 | 0.01 | 2.2 | 75.9 |
| 50 | 0.000210 | 4769.37 | 0.01 | 9.2 | 39.3 | 78 | 0.000014 | 8515.08 | 0.03 | 5.5 | 45.5 |
| 51 | 0.000001 | 4912.43 | 0.08 | 16.2 | 46.2 | 79 | 0.000000 | 8769.82 | 0.13 | 1.8 | 75.9 |
| 52 | 0.001204 | 4970.74 | 0.02 | 8.5 | 24.0 | 80 | 0.000012 | 9234.08 | 0.04 | 0.4 | 111.5 |
| 53 | 0.000000 | 4993.46 | 0.02 | 16.4 | 93.9 | 81 | 0.000004 | 9664.66 | 0.13 | 1.0 | 124.7 |
| 54 | 0.000010 | 5051.08 | 0.10 | 7.7 | 40.8 | 82 | 0.000001 | 9909.45 | 0.33 | 2.5 | 86.9 |
| 55 | 0.000000 | 5064.87 | 0.04 | 18.0 | 58.3 | 83 | 0.000001 | 10102.78 | 0.38 | 4.8 | 69.6 |
| 56 | 0.000002 | 5174.39 | 0.23 | 10.3 | 42.1 | 84 | 0.000000 | 10629.36 | 0.10 | 2.0 | 62.5 |
| 57 | 0.000148 | 5279.98 | 0.10 | 2.6 | 109.0 | 85 | 0.000000 | 10816.78 | 0.40 | 1.5 | 67.0 |
| 58 | 0.000000 | 5454.47 | 0.03 | 2.8 | 69.0 | 86 | 0.000003 | 11399.71 | 0.40 | 0.5 | 76.9 |
| 59 | 0.000003 | 5727.54 | 0.03 | 1.8 | 69.7 | 87 | 0.000057 | 11962.76 | 0.30 | 0.3 | 67.4 |
| 60 | 0.000113 | 5825.64 | 0.10 | 1.6 | 84.1 | 88 | 0.000000 | 12716.59 | 0.21 | 1.0 | 81.1 |
| 61 | 0.000001 | 5947.51 | 0.03 | 2.9 | 155.2 | 89 | 0.000000 | 12846.00 | 0.09 | 0.7 | 57.8 |
| 62 | 0.000001 | 6002.47 | 0.05 | 4.7 | 84.7 | 90 | 0.000000 | 13471.90 | 0.23 | 0.5 | 139.3 |
| 63 | 0.000000 | 6187.52 | 0.34 | 5.4 | 96.8 | 91 | 0.000954 | 14020.21 | 0.23 | 0.1 | 109.5 |
| 64 | 0.000046 | 6281.79 | 0.02 | 5.1 | 145.7 | 92 | 0.000000 | 14764.20 | 0.70 | 0.3 | 60.3 |
| 65 | 0.000012 | 6298.97 | 0.01 | 4.1 | 124.5 | 93 | 0.000016 | 16128.66 | 1.17 | 0.1 | 50.2 |
| 66 | 0.000000 | 6348.10 | 0.06 | 3.6 | 94.3 | 94 | 0.000008 | 16803.58 | 0.32 | 0.2 | 53.4 |
| 67 | 0.000000 | 6403.61 | 0.28 | 3.9 | 69.4 | 95 | 0.000002 | 19697.32 | 0.32 | 0.8 | 71.0 |
| 68 | 0.000000 | 6518.52 | 0.17 | 2.6 | 80.5 | ||||||
수수 종자의 펩타이드를 이용한 계통식별
수수 계통 간 펩타이드의 양적발현에서 유의성을 갖는 펩 타이드를 적용한 Heat map 분석은 각 수수 계통에서 높게 (붉은색, up-regulate) 또는 낮게(녹색, down-regulate) 발현 된 펩타이드를 잘 보여주고 있다(Fig. 3). 또한 Heat map은 유의성이 있는 펩타이드를 이용한 계통 간 근연관계(vertical grouping)를 보여주고 있다. 흥미로운 결과는 CM10과 Q10 모두에서 각 계통의 반복 간 근연거리가 가까운 위치에 모 여 있어, 이는 측정 반복 간 차이가 적었음을 의미하였다.

Fig. 3.
Heat map analysis using peaks of p < 0.01 detected on CM10 (A) and Q10 (B) arrays in twelve sorghum lines. †hypoglycemic soghum lines, M/Z: mass per charge수수 12계통간의 근연거리를 이용한 군집분석에서 CM10 의 경우, 12계통은 크게 3개의 군집을 형성하였다. 계통번 호 ‘135001’, ‘135002’, ‘135003’, ‘135028’, ‘135029’, 및 ‘135030’이 한 군집을, ‘135004’와 ‘135009’가 두 번째 군 집을, ‘135004’, ‘135005’, ‘135007’ 및 ‘135008’이 세 번째 군집을 형성하였다. 흥미롭게도 혈당 강하 수수로 선정된 계 통 ‘135007’을 제외한 나머지 혈당 강하 수수 6계통 ‘135001’, ‘135002’, ‘135003’, 135028‘, ’135029‘, 및 ’135030‘이 한 군집으로 분리되었다는 것이다. 이러한 혈당 강하 계통의 군집은 Q10의 결과에서 더욱 뚜렷하게 나타났다. CM10에 서 비 혈당 강하 군집으로 분리된 ‘135007’이 Q10에서는 혈당 강하 계통 군집으로 형성하였고, 비 혈당 강하 계통들 이 다른 한 군집을 형성하였다. 이는 혈당 강하 계통과 비 혈당 강하 계통에서 특이적으로 발현되는 고유의 펩타이드 가 각각 존재함을 제시하고 있다.
혈당 강하 수수 종자의 특이적 발현 펩타이드 분석
수수 12계통을 혈당 강하 계통군과 비 혈당 강하 계통군 의 2군으로 분류하여 펩타이드의 양적 발현을 비교하였다. 분자량의 범위가 2~20 kDa에서 검출된 펩타이드 양적발현 에서 2군 간 유의성(p < 0.01)을 보인 펩타이드는 CM10에 서 26개와 Q10에서 29개였다. 그러나 p < 0.01의 유의성이 있는 펩타이드의 Heat map 군집 분석 결과는 CM10과 Q10 모두에서 혈당 강하군과 비 혈당 강하군을 군집화하지 못하 였다. 혈당 강하군과 비 혈당 강하군의 군집화는 p < 0.00001 의 유의성이 있는 펩타이드로 가능하였으며(Fig. 4), 혈당 강하 계통 ‘135007’은 CM10에서는 비 혈당 강하군으로 되 었으나, Q10에서는 혈당 강하군으로 군집화 되었다. p < 0.00001의 유의성이 있는 펩타이드는 CM10에서는 13개 (Table 3)와 Q10에서는 16개(Table 4)가 선정되었다.
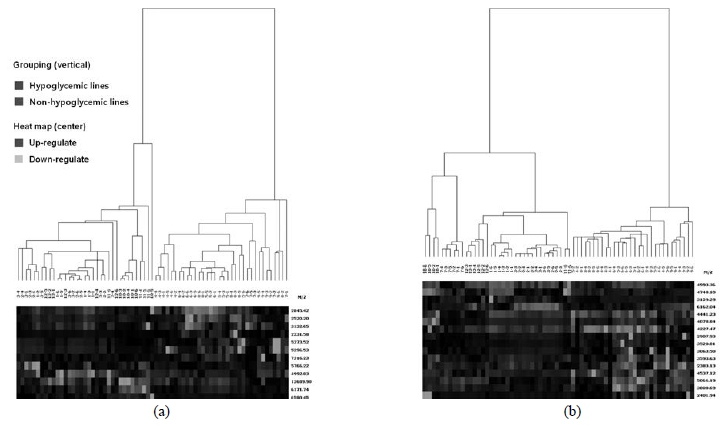
Fig. 4.
Heat map analysis using peaks of p < 0.00001 between non-hypoglycemic and hypoglycemic sorghum lines detected on CM10 (A) and Q10 (B) arrays. M/Z: mass per charge.Table 3.
Significantly different peptide peak (p < 0.00001) between non-hypoglycemic and hypoglycemic sorghum lines detected on CM10 array.
| index | p-value | M/Z† | Intensity | ||
|---|---|---|---|---|---|
| mean | CV (%) | mean | CV (%) | ||
| 1 | 0.0000000046 | 2231.57 | 0.02 | 11.5 | 71.2 |
| 2 | 0.0000001099 | 2520.07 | 0.02 | 10.3 | 84.8 |
| 3 | 0.0000001525 | 2845.37 | 0.02 | 10.1 | 102.9 |
| 4 | 0.0000000351 | 3132.89 | 0.03 | 16.5 | 61.1 |
| 5 | 0.0000000203 | 4993.24 | 0.03 | 11.4 | 50.9 |
| 6 | 0.0000000604 | 5295.93 | 0.02 | 13.6 | 124.0 |
| 7 | 0.0000006190 | 5373.13 | 0.03 | 10.8 | 124.3 |
| 8 | 0.0000002908 | 5775.80 | 0.04 | 9.0 | 104.9 |
| 9 | 0.0000098427 | 6173.69 | 0.05 | 7.9 | 102.3 |
| 10 | 0.0000000403 | 6589.99 | 0.03 | 5.5 | 76.8 |
| 11 | 0.0000056061 | 7318.30 | 0.09 | 4.3 | 89.4 |
| 12 | 0.0000066471 | 9415.52 | 0.08 | 4.0 | 61.5 |
| 13 | 0.0000029703 | 12738.63 | 0.09 | 1.1 | 81.8 |
Table 4.
Significantly different peptide peak (p < 0.00001) between non-hypoglycemic and hypoglycemic sorghum lines detected on Q10 array.
| index | p-value | M/Z† | Intensity | ||
|---|---|---|---|---|---|
| mean | CV (%) | mean | CV (%) | ||
| 1 | 0.0000000042 | 2383.76 | 0.07 | 11.5 | 66.9 |
| 2 | 0.0000000045 | 2401.74 | 0.02 | 6.1 | 73.0 |
| 3 | 0.0000000078 | 2907.95 | 0.01 | 11.5 | 113.5 |
| 4 | 0.0000000572 | 3063.57 | 0.01 | 5.6 | 106.5 |
| 5 | 0.0000000002 | 3129.36 | 0.02 | 4.7 | 95.0 |
| 6 | 0.0000000019 | 3520.60 | 0.03 | 15.2 | 93.5 |
| 7 | 0.0000001012 | 3593.91 | 0.03 | 7.8 | 84.8 |
| 8 | 0.0000000178 | 3808.91 | 0.02 | 10.4 | 59.7 |
| 9 | 0.0000003512 | 4078.68 | 0.01 | 33.9 | 132.8 |
| 10 | 0.0000000067 | 4226.43 | 0.04 | 8.2 | 61.7 |
| 11 | 0.0000000036 | 4441.31 | 0.02 | 8.9 | 107.3 |
| 12 | 0.0000000022 | 4537.12 | 0.01 | 4.7 | 80.1 |
| 13 | 0.0000000039 | 4747.97 | 0.02 | 15.2 | 64.8 |
| 14 | 0.0000000097 | 4993.46 | 0.02 | 16.4 | 93.9 |
| 15 | 0.0000000001 | 5065.00 | 0.05 | 18.1 | 57.3 |
| 16 | 0.0000004020 | 6200.20 | 0.04 | 5.6 | 88.0 |
수수 혈당 강하 계통군에서 특이적으로 양적발현이 높은 펩타이드를 분석하기 위하여, 혈당 강하군과 비 혈당 강하 군 간 p < 0.00001 수준에서 유의성이 있는 29개 펩타이드 (CM10의 13개와 Q10의 29개)를 group scatter plot 으로 양 적발현을 비교 분석하였다(Fig. 5). 분석결과, 분자량이 5 kDa 이하에서 총 10종의 펩타이드가 선정되었다. CM10에서 는 분자량이 2231.57, 2845.42, 3132.64, 5296.52, 5375.51 Da을 포함한 5종이, Q10에서는 분자량이 2907.92, 3063.49, 3520.81, 4078.83, 5066.18 Da의 5종의 펩타이드가 수수 혈 당 강하 계통 군에서만 특이적으로 양적발현이 높은 펩타이 드로 선정되었다.
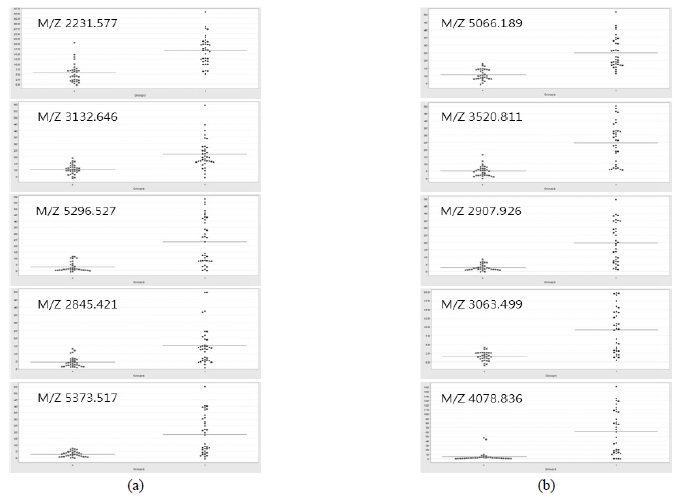
Fig. 5.
Group scatter plots of selected potential peptide biomarkers (p < 0.00001) for hypoglycemic sorghum detected on CM10 (A) and Q10 (B) arrays. Left : Non-hypoglycemic, Right : Hypoglycemic sorghums, |M/Z: mass per charge.본 연구의 SELDI-TOF MS 기법을 활용한 수수 종자의 펩타이드를 분석한 결과, 수수 12 계통은 각각의 고유한 종 자 유래 펩타이드 프로파일과 유의성이 있게 발현하는 특이 적 펩타이드가 존재하였으며, 고유한 펩타이드 프로파일을 이용한 품종 및 계통의 식별과 선발에 적용할 수 있음을 시 사하고 있다. 또한 혈당 강하 계통과 비 혈당 강하 계통의 펩타이드 분석을 통하여 2개의 군이 서로 다른 군집으로 분 류되었으며, 이는 혈당 강하 계통과 관련된 특이적으로 발 현하는 일련의 펩타이드군이 있음을 제시하였다. 혈당 강하 계통에서 유의성(p < 0.00001) 이 있게 발현되는 펩타이드 를 29개 선정하였으며, 이중에서 펩타이드의 양적 발현이 혈당 강하 계통에서만 공통적으로 높은 10개의 펩타이드가 선발되었다. 따라서 이들 펩타이드는 혈당 강하 수수 품종 의 선발에 종자 펩타이드를 기반으로 한 바이오마커로 이용 할 수 있음을 제시하였다.
적 요
혈당 강하를 목적으로 선발된 수수계통의 종자 유래 펩타 이드의 양적, 질적 형질을 특성화하고 혈당 강하 수수에서 특이적으로 발현 펩타이드를 선발하기 위하여, 혈당 강하 수수 7계통과 비 혈당 강하 수수 5계통에 대한 종자 펩타이 드 프로파일링을 SELDI-TOF MS 기법을 활용하여 분석하 였다.
분자량의 범위가 2~20 kDa에서 검출된 수수 12계통 종자의 펩타이드는 CM10 (weak cation exchanger)에 서 104개와 Q10 (strong anion exchanger)에서 95개였 으며, 펩타이드 양적발현에서 12계통 간 유의성(p < 0.01)을 보인 펩타이드는 CM10에서 99개와 Q10에서 93개였다.
12계통 간 양적 발현에 유의적(p < 0.01) 펩타이드를 이용한 heat map 분석에서 수수 각 계통 종자의 고유 한 펩타이드 프로파일과 특이적으로 발현하는 펩타이 드를 제시하고 있다.
수수 12계통간의 근연거리를 이용한 군집분석에서 혈 당 강하 수수 7계통과 비 혈당 강하 수수 5계통이 서 로 다른 2개의 군집을 형성하였다.
혈당 강하 계통에서 유의성(p < 0.00001)이 있게 발현 되는 펩타이드를 29개 선정하였으며, 이중에서 혈당 강하 계통에서만 공통적으로 높게 발현된 10개의 펩타 이드(분자량이 2231.6, 2845.4, 2907.9, 3063.5, 3132.6, 3520.8, 4078.8, 5066.2, 5296.5, 5375.5 Da)를 선발하 였다.
