

서 론
연구 방법
데이터 수집 및 구성
데이터 전처리
변수선택
다변량 차원 축소 분석
모델 개발
연구 수행 도구
결과 및 고찰
데이터 탐색 및 전처리 결과
주성분 분석 결과
군집 분석 결과
Preference Map 분석 결과
변수선택 결과
머신러닝 모델의 지도학습과 성능 평가 결과
SHAP Value 분석 결과
선행연구와의 비교
적 요
서 론
농업은 인류 문명의 근간이며, 최근 디지털 기술의 발전으로 농업 데이터가 급증함에 따라 머신러닝(ML) 기법의 활용이 주목받고 있다(Zhou et al., 2017). 식품 품질 평가, 특히 식량작물의 감각검사는 평가자의 주관성, 비용, 반복의 한계 등 구조적 제약을 지닌다. 머신러닝은 이러한 다변량 비선형 관계를 학습하여 감각평가를 보완할 유망한 대안으로 부상하고 있다(Schreurs et al., 2024).
국립식량과학원은 지난 10여 년간 쌀 품질 및 밥맛 기호도 데이터를 체계적으로 축적해 왔으며, 이는 모델 학습 및
해석에 적합한 기반 데이터를 제공한다. 본 연구는 이 데이터를 활용하여 (1) 차원축소(PCA)와 군집분석을 통해 품질 특성 구조를 규명하고, (2) GBM (Gradient Boosting Machine)과 Random Forest 모델을 이용해 밥맛 기호도 총평을 예측하며, (3) SHAP (SHapley Additive exPlanations) 값을 통해 주요 품질 변수의 영향을 해석하는 것을 목표로 한다. 이를 통해 감각검사의 효율성과 객관성을 높이는 머신러닝 기반 품질 평가 체계의 가능성을 제시하고자 한다.
연구 방법
데이터 수집 및 구성
본 연구에서는 지난 10여 년간 축적된 쌀 품질 및 밥맛 기호도 평가 데이터를 활용하여 머신러닝 모델을 개발하였다. 주요 데이터는 국립식량과학원의 「벼 신품종 육성 및 이용촉진사업 보고서」(2011~2019)와 「벼 신품종 개발 공동연구보고서」(2020~2022)에서 수집된 미질 특성 자료와, 같은 기관 중부작물부에서 실시한 밥맛 기호도 평가 결과를 포함한다. 데이터 세트에는 벼의 품종 및 계통 정보와 함께 입형 특성(정조 길이, 너비, 두께, 장폭비 등), 이화학적 특성(아밀로스 함량, 단백질 함량, 윤기치 등), 도정 특성(제현율, 현백율, 백미 완전미율, 싸라기율, 피해립률 등), 기호도 평가 항목(총평)이 포함되었다(Table 1). 기호도 항목은 7점 등간 척도(-3=매우 나쁨, ..., +3=매우 좋음)로 평가하였으며, 패널 점수는 계통 단위로 평균하여 분석에 활용하였다. 총 297개 시료가 포함되었으며, 수집된 데이터는 전처리를 수행한 후 통합하여 머신러닝 모델 학습에 활용하였다.
Table 1.
Composition of the collected dataset.
| Category | Measured Traits | Variables |
| Lines and Cultivars | Sampling information |
297 samples collected from 2011 to 2022 |
| Morphological Characteristics | - |
(Rough rice) Length, Width, Thickness, Length/Width Ratio (Brown rice) Length, Width, Thickness, Length/Width Ratio |
| Physicochemical Characteristics | Grain composition and glossiness |
ADV*, Amylose(%), Protein (%), Toyo Value for Glossiness |
| Milling Characteristics | Milling recovery ratio(%) |
Brown/Rough Ratio, Milled/Brown Ratio, Milled/Rough Ratio, |
| Grain processing traits |
Head Rice (%), Chalky Rice (%), Broken Rice (%), Damaged Rice (%) Head rice milling recovery ratio | |
| Palatability Result | Sensory evaluation | Overall Score |
데이터 전처리
수집된 데이터에 대하여 결측치 처리, 이상치 제거, 변수 스케일 조정 등의 전처리 과정을 수행하였다. 먼저 결측치는 탐색적 데이터 분석(Exploratory Data Analysis, EDA)을 통해 확인하였으며, 결측률(>21%)이 높은 시료는 분석에서 제외하였으며, 이상치는 마할라노비스 거리(Mahalanobis Distance)를 이용하여 다변량 분포를 기반으로 탐지하였다(Supplementary Table S3). 자유도(df)=9, 신뢰수준 97.5%의 χ2 분포 경계 밖에 위치한 시료를 이상치로 판단하여 제거하였다. 결측치와 이상치 제거 후 216개 시료 데이터를 모델의 지도 학습에 사용 하였다.
연속형 변수에 대해서는 평균 0, 표준편차 1로 변환하는 표준화(Standardization)를 적용하였으며, 이를 위해 계산된 평균 및 표준편차 값은 별도로 저장하여 추후 새로운 데이터에도 동일한 변환을 적용할 수 있도록 하였다(Supplementary Table S2).
변수선택
본 연구의 변수선택 과정은 훈련 데이터 세트만을 이용해 정보 누출을 방지했으며, 다음과 같은 세 단계로 구성되었다: ① 상관분석, 주성분분석(PCA), 군집분석 및 Preference Map 분석 등 다변량 차원 축소 분석 결과를 바탕으로 밥맛 예측에 기여할 가능성이 높은 주요 품질 특성을 입력변수 후보로 선정하였다. ② 이후 GBM과 Random Forest의 예비 모델링으로 변수 중요도를 산출하였다. ③ 모델별 변수중요도를 정규화한 뒤 평균하여 결합 중요도를 산출하고, 해석을 기반으로 최종 변수를 선택하였다(Greenwell et al., 2018). 이를 통해 과적합(Overfitting)을 방지하고, 모델의 해석 가능성과 예측 효율을 동시에 확보하고자 하였다(Pudjihartono et al., 2022).
다변량 차원 축소 분석
PCA 분석
주성분분석(PCA)에 앞서, 변수 간 상관 구조의 적합성을 검증하기 위해 KMO (Kaiser-Meyer-Olkin) 검정과 Bartlett의 구형성 검정을 실시하였다. KMO 검정 결과는 0.47로 다소 낮았으나, Bartlett 구형성 검정은 통계적으로 유의(χ2(190) =4170.3, p < 0.001)하여 변수 간 유의미한 상관이 존재함을 확인하였다. KMO 값이 낮다는 것은 변수 간 공통 요인이 약함을 시사할 수 있으나, 본 연구의 목적은 요인 추출(Factor Analysis)이 아닌 데이터의 구조적 분산 패턴을 탐색하고 요약하는 탐색적 PCA이다. 따라서 유의한 Bartlett 검정 결과를 근거로, 고차원 품질 특성 변수를 저차원의 주성분으로 요약하고 시각화하기 위해 PCA를 수행하였다. 이를 위해 관측 변수를 선형 결합한 주성분을 추출하여 미질 특성의 구조를 구명하고자 하였으며, 모든 변수는 표준화하여 분석에 동일한 가중치로 기여하도록 하였다. 이후, 주요 주성분의 분산 기여율과 변수 부하량(loadings)을 산출하였다.
군집분석
쌀 시료 간 유사도 기반 그룹화를 위해 K-평균 군집화(K-means clustering)를 적용하였다. NbClust 패키지를 이용하여 다양한 평가 지표(실루엣 계수, CH 지수 등)를 종합적으로 검토한 결과, 26개의 지표 중 12개의 지표가 3개의 군집을 지지하여 최적 군집 수는 3개로 결정하였다(Supplementary Fig. S1). 또한 엘보(elbow) 기법을 통해 군집 내 응집도와 군집 간 분산의 변화를 시각적 확인한 결과, 3개 군집이 가장 적절한 구조로 나타났다(Supplementary Fig. S2)
Preference Map 분석
군집 분석 결과와 기호도 평가 데이터를 종합적으로 해석하기 위해 Preference Mapping 기법을 적용하였다. Preference Map은 소비자 기호도 데이터와 제품 특성 데이터를 통합하여, 제품들 간의 상대적인 기호도 위치를 2차원 공간에 시각화하는 감각평가 분석 기법이다(Faye et al., 2006). SensMap 패키지를 활용하여 PCA로 축약된 품질 특성 공간 상에 각 군집의 평균 기호도 점수(총평)를 투영하였다. 이를 통해 군집별 쌀 시료의 위치와 기호도 총평과의 관계를 시각적으로 표현하고, 품질 특성과 기호도 점수의 연관성을 분석하였다.
모델 개발
본 연구에서는 GBM, Random Forest의 두 가지 앙상블 모형을 적용하여 기호도 총평의 이진 분류 예측을 수행하였다. 입력변수는 앞서 언급한 변수 선택 결과에 따라 설정하였으며, 목표 변수(총평)는 기준 품종 ‘추청’ 총평과의 차이를 Δ로 하고, - A(우수): Δ ≥ 0.0 - B(열등): Δ < 0.0 의 이진 범주로 정의하였다. 이러한 이진 분류 접근은 실제 벼 육종 현장에서 육종가들이 대비 품종을 기준으로 신규 계통의 선발 여부를 결정하는 Go/No-Go 의사결정 과정을 직접적으로 반영한다. 따라서 본 모델은 회귀나 다중 분류 모델보다 현장 적용성 및 실용적 가치가 높다고 판단하였다. 데이터 분할과 재표본추출 및 모델 학습은 set.seed (123)으로 고정하여 재현성을 확보하였다. 변수선택은 오직 훈련 세트 내부 교차검증 단위에서 수행되었고, 테스트 세트에는 훈련 세트에서 추정된 파라미터 및 최종 선택 변수만을 적용하였다.
모델 학습 및 하이퍼파라미터 설정
전체 데이터는 훈련 세트(80%, n = 174)와 테스트 세트(20%, n = 42)로 분할하였으며, 각 세트에서 A/B 클래스 비율이 원 데이터와 동일하도록 층화 분할(stratified split)을 수행하였다(Supplementary Table S1). 훈련 세트에 대해서는 5-fold 교차검증을 적용하였으며, 모델 학습과 하이퍼파라미터 탐색은 caret::train() 함수를 이용하여 동시에 수행하였다. 하이퍼파라미터 최적화 과정에서는 분류 정확도(Accuracy)를 기준으로 가장 우수한 조합을 선택하였다.
그 결과, GBM 모델의 최적 하이퍼파라미터는 트리 수(n.trees)=200, 트리 깊이(interaction.depth)=2, 학습률(shrinkage)= 0.05, 노드 최소 관측치(n.minobsinnode)=10이 최적값(정확도=0.7345)으로 결정되었다. Random Forest 모델의 경우, mtry=5, 트리 수(ntree)=500에서 가장 높은 교차검증 정확도(0.7305)를 보여 최적 하이퍼파라미터로 채택하였다(Table 2).
Table 2.
Model accuracy and optimized hyperparameters after cross-validation.
모델 성능 평가 및 모형 해석
모델의 최종 예측 성능을 검증하기 위하여, 훈련 단계에서 최적화된 하이퍼파라미터를 적용한 두 모델을 독립된 테스트 세트(20%)로 평가하였다. 혼동행렬(confusion matrix)과 ROC (Receiver Operating Characteristic) 곡선 기반으로 수행하였으며, 이를 통해 클래스별 예측 결과로부터 주요 평가지표를 산출하였다. 산출된 평가지표는 정확도, 카파계수(Kappa coefficient), 민감도(Sensitivity), 특이도(Specificity), 정밀도(Precision)로 구성되었다. 이들 지표는 모델의 전반적인 예측력과 클래스 간 구분의 균형성을 종합적으로 평가하기 위함이다. 또한 ‘No Information Rate (NIR)’ 대비 정확도의 통계적 유의성 검정을 통해 모델의 분류 성능이 무작위 예측보다 유의하게 우수한지를 확인하였다. 모형 해석을 위해서는 SHAP (Shapley Additive Explanations)을 적용하여 변수 중요도와 예측값에 대한 영향 방향을 추정하였다.
연구 수행 도구
데이터 전처리부터 통계 분석, 머신러닝 모델링까지 전 과정은 Jamovi 2.2 및 R 4.3.2 (RStudio 2023.12.1+402) 소프트웨어 환경에서 수행되었다. 주요 R 패키지로는 머신러닝 모델 구축 및 평가를 위한 caret, gbm, randomForest 차원 축소와 군집화를 위한 psych, REdaS, FactoMineR, factoextra, cluster, NbClust, 감각 분석을 위한 SensMap, SHAP 분석을 위한 shapr, kernelshap, 그리고 데이터 전처리·시각화를 위한 dplyr, ggplot2 등을 활용하였다.
결과 및 고찰
데이터 탐색 및 전처리 결과
수집된 쌀 품질 및 기호도 데이터에 대해 탐색적 자료 분석(Exploratory Data Analysis, EDA)을 통해 일부 품질 특성 변수에서 분포 불균형이 확인되었다. 297개 시료의 기본 통계량과 함께 왜도(skewness) 및 첨도(kurtosis)를 산출한 결과, 도정 특성 중 싸라기율과 피해립률이 각각 왜도 4.08, 6.48, 첨도 21.50, 64.30으로 극단적인 비대칭 분포를 보였다(Table 3, Fig. 1). 이러한 심한 비대칭 분포는 머신러닝 지도학습 과정에서 특정 범주의 과적합이나 예측 성능 저하를 초래할 수 있으므로(Ryu, 2011), 이에 분상질립률·싸라기율·피해립률·완전미 도정수율 등 극단치를 보이는 변수는 모델 분석에서 제외하였다.
Table 3.
Exploratory data analysis (EDA) of the collected dataset.
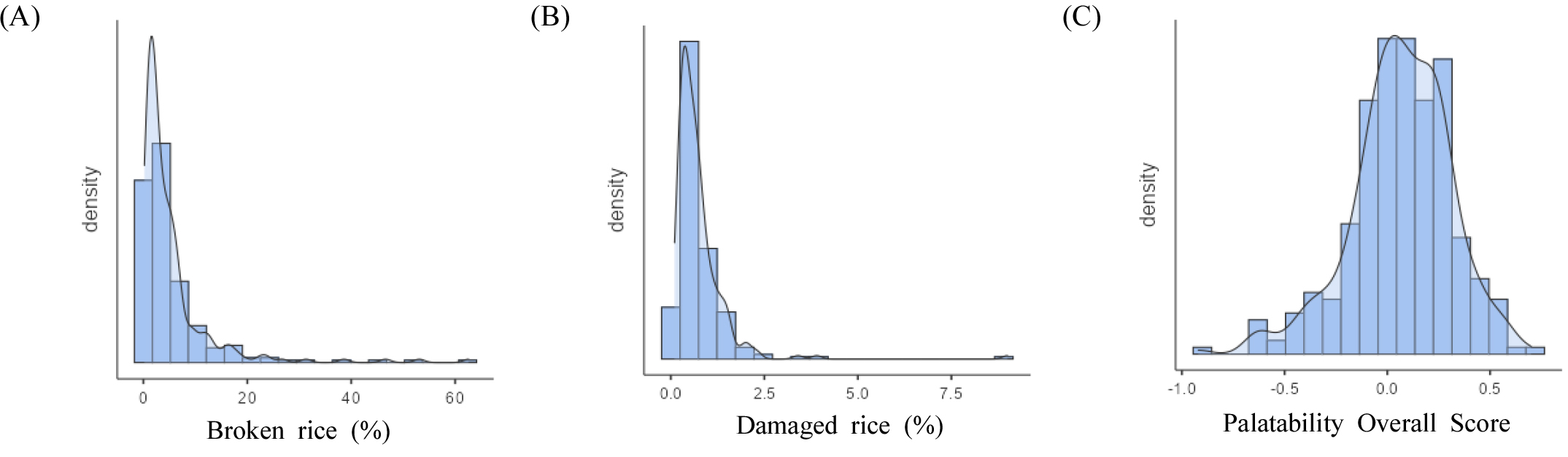
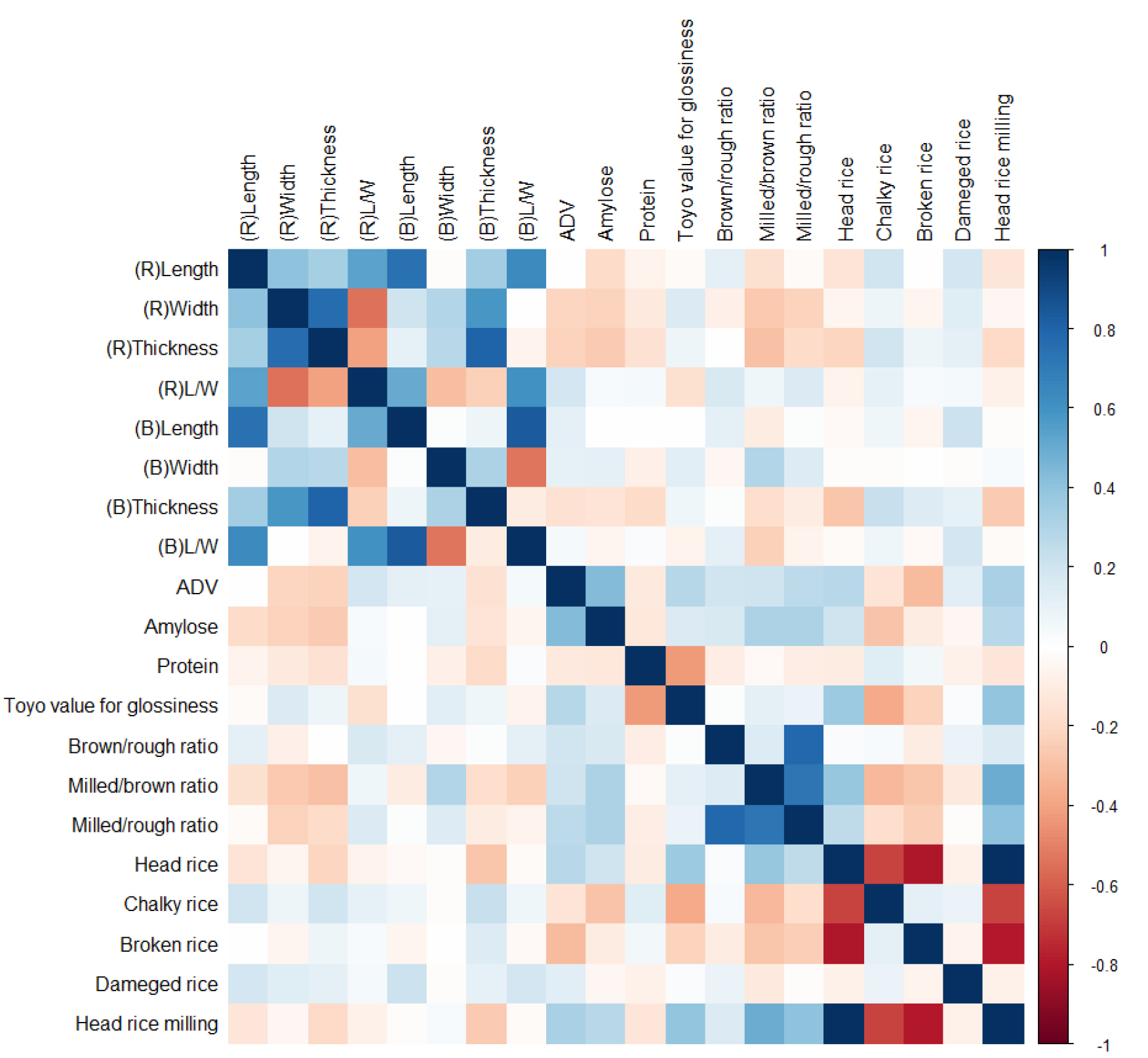
한편, 예측 대상으로 설정한 기호도 점수는 비교적 정규분포에 가까운 균일한 분포를 보여, 목표 변수가 심각한 불균형을 나타내지는 않았다(Table 3, Fig. 1). 변수들 간의 상호 상관성 분석 결과, 입형 특성과 도정 특성 변수들 사이에 유의하게 높은 상관관계가 다수 확인되었다(Table 4, Fig. 2). 예를 들어 정조의 길이·너비·두께 간 또는 도정 관련 지표들 간 피어슨 상관계수가 높게 나타나, 데이터 내 다중공선성(multicollinearity) 문제가 존재할 가능성이 확인되었다. 독립변수들 간 높은 상관성은 모델의 신뢰성과 예측 정확도를 저하시킬 수 있으며, 변수 해석 시 각 요인의 독립적인 기여도를 판단하기 어렵게 만든다(Chan et al., 2022). 이러한 문제를 해결하기 위해, 변수선택 단계에서는 상관계수가 높은 정조와 현미의 입형 특성 중 정조 관련 변수를 제거하여 다중공선성을 완화하였다. VIF(Variance Inflation Factor) 분석 결과, 정조·현미 입형 관련 변수(정조길이·정조너비·현미길이 등) 및 일부 가공 특성(현백율·도정율·제현율)은 VIF가 100을 초과하는 매우 높은 수준으로 나타났다 (Supplementary Table S4). 이는 동일 계열 변수들이 강한 상관성을 가지며 구조적으로 중복되는 정보를 포함하고 있음을 의미하며 , 각 변수군별 대표성을 고려한 변수 선택이 타당함을 뒷받침한다. 이와 같이 EDA 및 상관분석을 통해 확보된 정보는 데이터의 품질과 신뢰성을 진단하고, 안정적인 머신러닝 모델 학습을 위한 기반 자료로 활용되었다.
Table 4.
Correlation coefficients among rice quality traits; (A) grain shape traits, (B) milling traits.
주성분 분석 결과
품질 특성에 대한 PCA에서는 윤기치, 백미 완전미율, 현미길이, 현미두께가 주요 변동에 크게 기여하였다. 주성분 1(Dim1)은 Amylose, 윤기치와 백미 완전미율 등의 높은 부하량으로 보아 이화학 및 도정 품질 축으로, 주성분 2·3(Dim2·Dim3)은 정조 및 현미의 입형 특성을 주로 반영하는 축으로 해석된다(Table 5, Fig. 3). 이러한 구조는 유사 속성의 변수가 동일 축에 응집되는 경향을 보여 주며, 앞선 상관분석 결과와도 일치하였다.
Table 5.
Variable loadings of rice quality traits by principal components (Dim1-Dim3).
| Variable |
First principal component (Dim 1) |
Second principal component (Dim 2) |
Third principal component (Dim 3) | ||
| (R)Length* | -0.333 | 0.224 | 0.781 | ||
| (R)Width | -0.324 | 0.776 | 0.300 | ||
| (R)Thickness | -0.383 | 0.795 | 0.207 | ||
| (R)L/W | 0.050 | -0.648 | 0.372 | ||
| (B)Length* | -0.144 | -0.053 | 0.819 | ||
| (B)Width | 0.067 | 0.630 | -0.177 | ||
| (B)Thickness | -0.315 | 0.777 | 0.092 | ||
| (B)L/W | -0.160 | -0.470 | 0.783 | ||
| ADV | 0.219 | -0.126 | -0.01 | ||
| Amylose | 0.554 | -0.037 | 0.005 | ||
| Protein | -0.238 | -0.285 | 0.002 | ||
| Toyo Value for Glossiness | 0.548 | 0.368 | 0.021 | ||
| Brown rice ratio | 0.325 | 0.137 | 0.247 | ||
| Head brown rice ratio | 0.749 | 0.112 | -0.119 | ||
| Milling ratio | 0.659 | 0.159 | 0.109 | ||
| Head rice | 0.846 | 0.107 | 0.232 | ||
| Chalky rice | -0.662 | -0.107 | -0.101 | ||
| Broken rice | -0.604 | -0.084 | -0.295 | ||
| Damaged rice | -0.091 | -0.053 | 0.296 | ||
| Head Rice Milling Recovery Ratio | 0.897 | 0.125 | 0.239 | ||
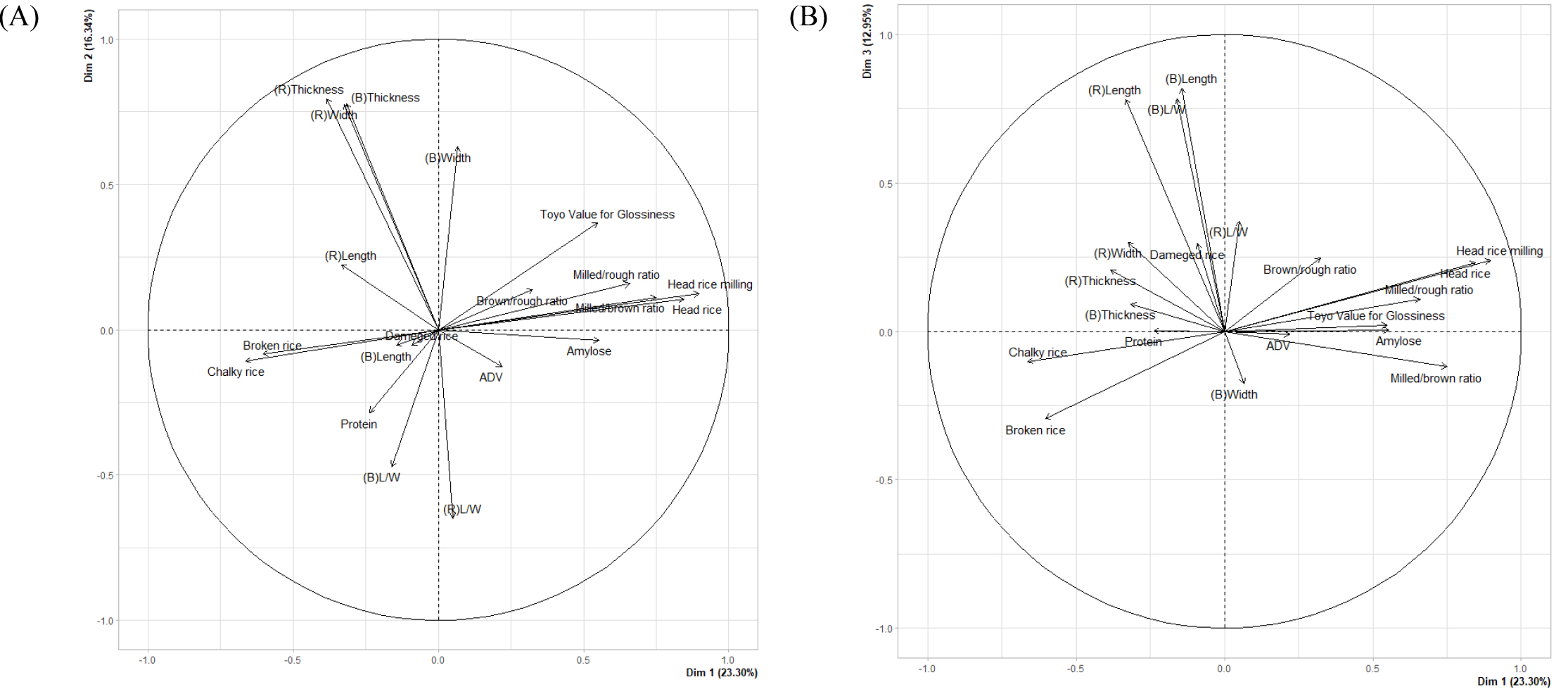
아울러 품질 특성에 대한 PCA에서는 주성분 1-3이 전체 분산의 약 52.6%를 설명하여 데이터의 주요 패턴을 요약하였으나, 잔여 주성분의 누적 기여도도 47.4%에 달한다(Table 6). 따라서 핵심 축 중심의 해석은 유효하되, 모델 구축 시 잔여 차원에 내재한 정보 손실을 최소화하도록 다양한 특성을 균형 있게 고려할 필요가 있다. 종합하면, Amylose와 일부 도정 및 입형 특성이 데이터 변동의 주요 요인임을 확인하였다. 이 결과는 후속 군집화 및 예측 모델링 단계에 유용한 근거를 제공한다.
Table 6.
Explained variance, and cumulative variance of principal components for rice quality traits.
군집 분석 결과
K-means 군집화 결과 NbClust 지표와 엘보 기법에 근거해 3개 군집이 최적임을 확인하였다(Supplementary Fig. S1, S2). PCA 평면에 투영했을 때 군집 간 품질 특성이 명확히 구분되었다(Fig. 4). 군집 1은 윤기치·현미너비·완전미 도정수율이 높아 전반적으로 양호한 미질 특성을 보였고, 군집 2는 정조길이가 길고 싸라기율·분상질률이 높아 품질 저하 요인이 많았다. 군집 3은 단백질 함량이 높은 경향을 보였다. 이로써 쌀 품종이 외관·이화학·도정 특성에 따라 뚜렷한 그룹을 형성함을 확인하였다.
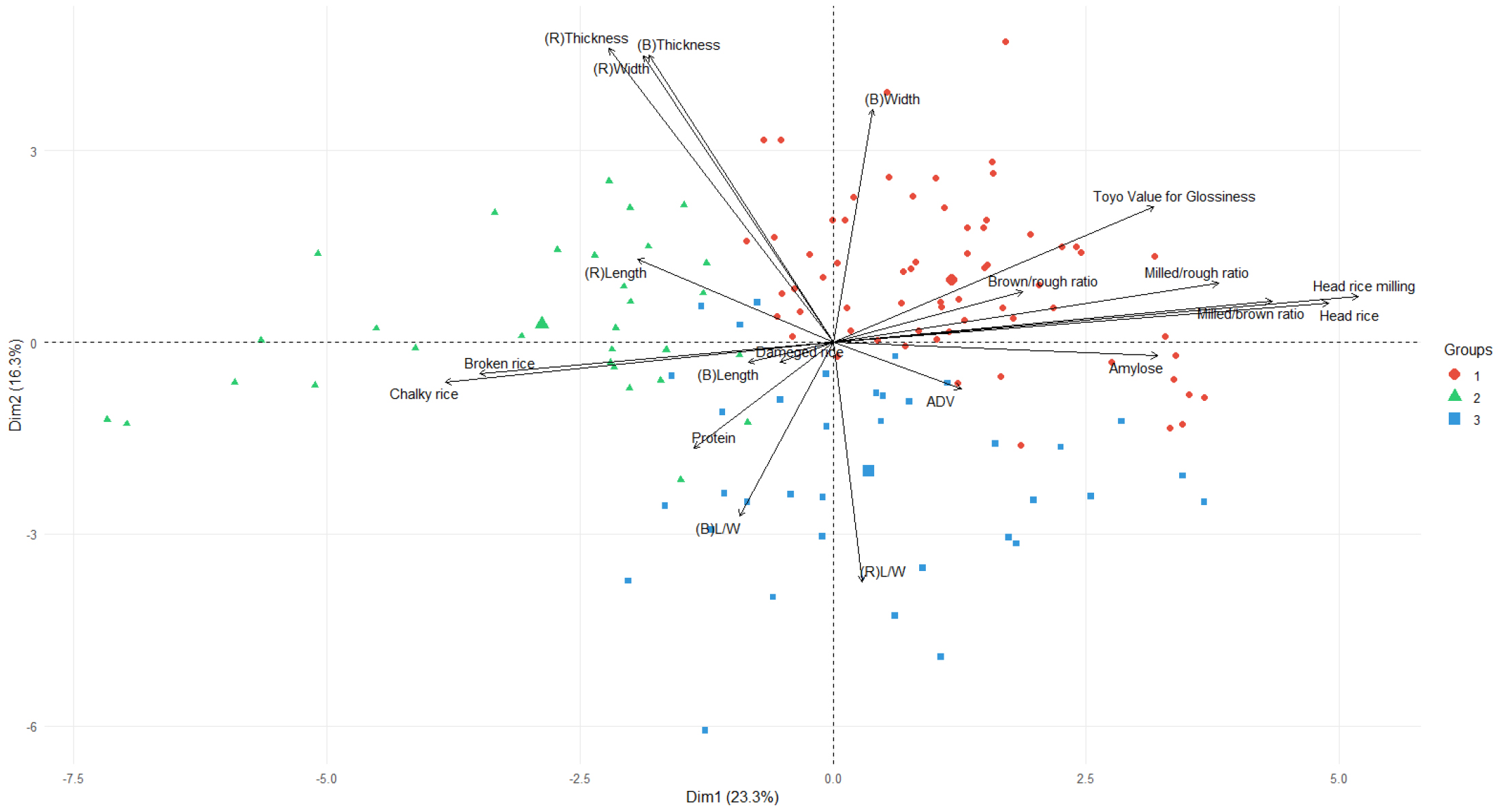
Fig. 4.
K-means clustering of collected rice lines visualized on the PCA plot of quality traits; Each point represents a rice sample, and arrows indicate the direction and contribution of each variable to the principal components. Dim1 (23.3%) and Dim2 (16.3%) account for the largest proportions of variance in the data. Samples were classified into three clusters (Groups 1-3) based on multivariate similarities derived from morphological, physicochemical, and milling characteristics.
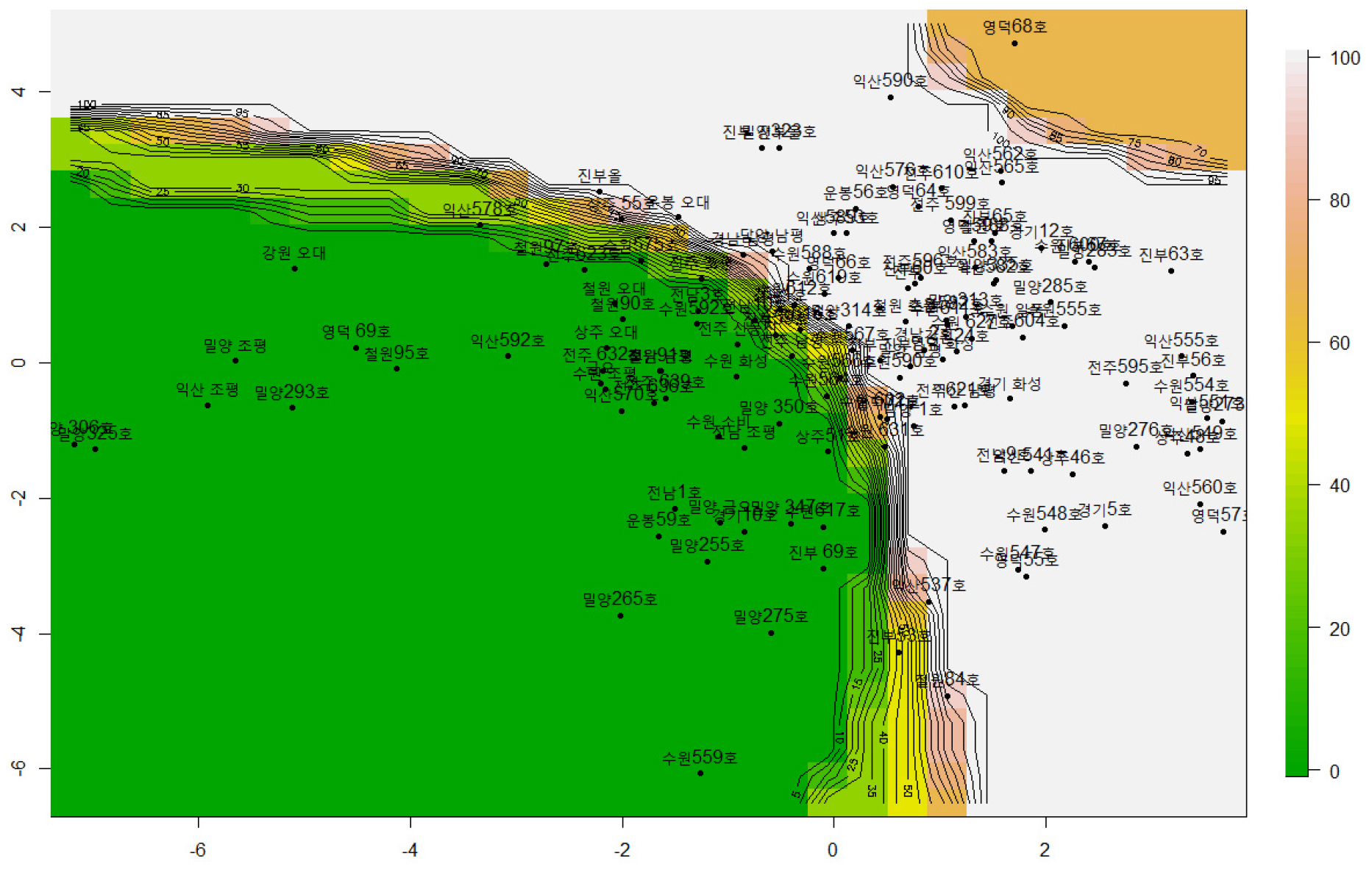
Preference Map 분석 결과
Preference Map 분석 결과, 군집별 품질 특성이 감각적 선호도와 밀접히 연관됨을 확인하였다(Fig. 5). 군집 1은 윤기치·완전미율이 높고 총평이 우수해 외관 품질이 밥맛 인상에 긍정적으로 작용함을 보였다(Li et al., 2023). 반면 군집2와 3은 총평 점수가 상대적으로 낮았다. 특히 군집 2는 분상질률·피해립률이 높고 윤기치가 낮아 외관·식감 저하와 관련된 부정적 요인으로 작용한 것으로 판단된다(Cuili et al., 2022). 이러한 군집 구조와 preference map 분석 결과는 예측모델 구축 시 변수 선택의 근거를 제공한다(Bhatnagar et al., 2018).
변수선택 결과
1.3절에서 기술한 다변량 차원 축소 분석 결과, 이화학적 특성(Amylose, 단백질, 윤기치), 도정 특성(백미 완전미율, 현백율), 입형 특성(현미길이, 현미두께, 장폭비)이 주요 변동 요인으로 확인되었다. 이 변수들을 기반으로 GBM과 Random Forest를 예비 모델링하여 변수 중요도를 산출하고, 최소-최대 정규화(0-1)한 뒤 평균하여 결합한 결과(Table 7.), Amylose, 현백율, 단백질, 현미길이, 윤기치의 기여도가 높았다. 반면 현미너비, 제현율 등은 중요도가 낮았다. 따라서 Amylose, 현백율, 단백질, 현미길이, 윤기치, 백미완전미율, 현미두께, 도정율을 최종 입력 변수로 선정하였다(Table 8).
Table 7.
Variable importance results derived from random forest and GBM models.
Table 8.
List of input variables used in machine learning models.
머신러닝 모델의 지도학습과 성능 평가 결과
훈련 데이터 세트에 대한 5-fold 교차검증을 통해 GBM과 Random Forest 모형의 최적 하이퍼파라미터를 결정하였으며, 결정된 모형을 독립된 테스트 세트에 적용하여 분류 정확도를 평가하였다(Tables 9, 10). Random Forest 모델은 전체 정확도(Accuracy) 0.7143으로 GBM (0.6429)보다 높았으며, Kappa 계수(0.4273) 또한 GBM (0.2792)보다 우수하였다. 이는 Random Forest 모델이 데이터 변동성에 더 강인하고 클래스 경계를 안정적으로 학습했음을 의미한다.
Table 9.
Confusion matrices of the GBM and Random Forest models on the test data set (42 samples).
| GBM | Reference |
Random Forest | Reference | |||||
| A | B | A | B | |||||
| Prediction | A | 16 | 9 | Prediction | A | 16 | 6 | |
| B | 6 | 11 | B | 6 | 14 | |||
Table 10.
Predictive performance of each model on the test data set.
두 모델 모두 A 클래스(우수)에 대한 민감도(Sensitivity)는 0.7273으로 동일하였으나, B 클래스(열등)의 특이도(Specificity)는 Random Forest (0.70)가 GBM (0.55)보다 높았다. 또한 Random Forest 모델의 정확도 향상 검정에서 p = 0.009로 통계적으로 유의하였으나, GBM은 p = 0.081로 유의하지 않았다.
GBM과 Random Forest 모델의 분류 성능을 ROC 곡선을 통해 비교하였다(Fig. 6, Supplementary Fig. S3). Random Forest의 ROC 곡선은 GBM보다 상단에 위치하고, AUC (Area Under the Curve) 값이 더 크게 나타나(GBM: 0.675, Random Forest: 0.722) 전반적인 분류 정확도와 특이도 수준에서 더 안정적인 성능을 확인할 수 있었다.
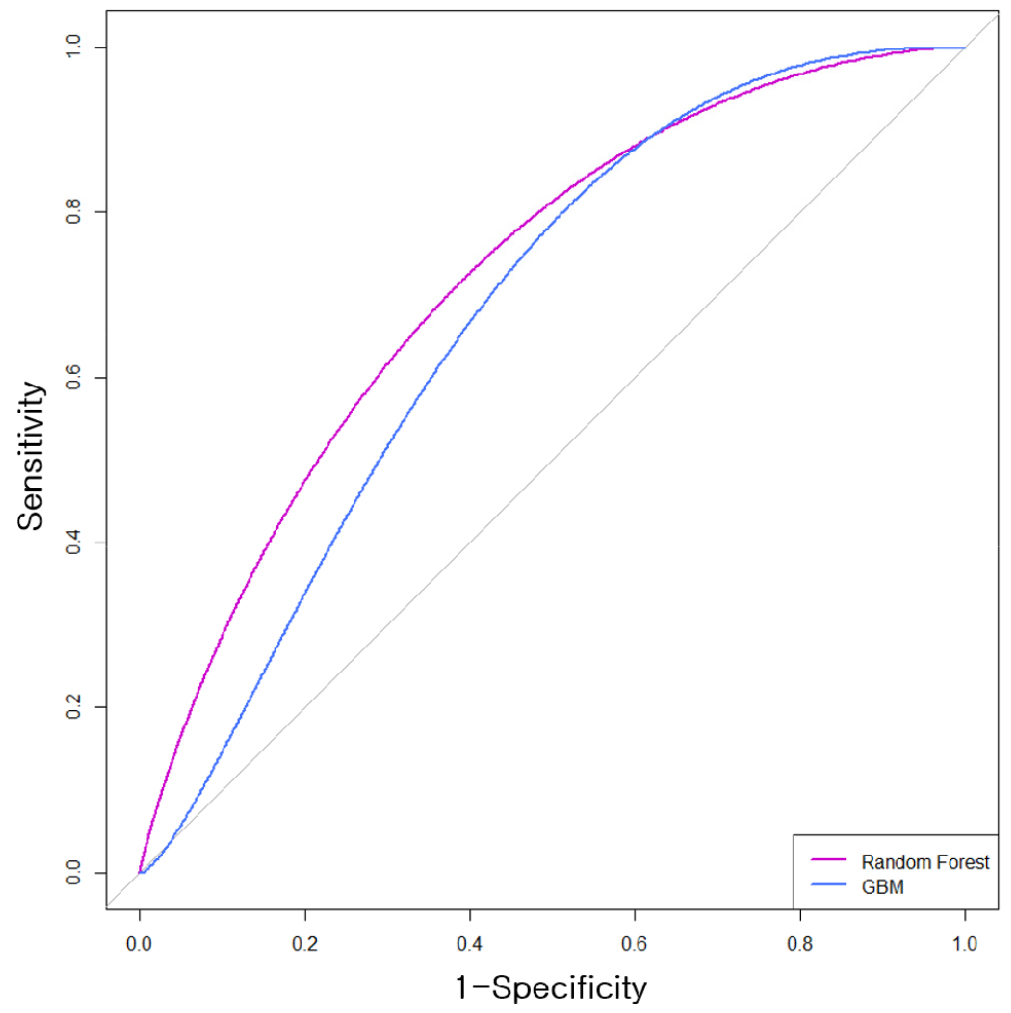
Fig. 6.
Comparison of ROC curves for Random Forest and GBM models. The ROC curves compare the classification performance between Random Forest (magenta line) and Gradient Boosting Machine (blue line) models for predicting rice eating quality. Random Forest exhibited a higher area under the curve (0.722), indicating superior discriminative ability compared to the GBM model (0.675).
종합하면 Random Forest 모델은 GBM 대비 높은 정확도와 안정적인 클래스 구분력을 보였으며, 테스트 세트에서도 통계적으로 유의한 일반화 성능을 확보하였다. 따라서 Random Forest 모델 기반 밥맛 등급 예측은 같은 복합 특성 기반 분류 문제에 보다 신뢰성 있는 예측 도구로 활용될 수 있을 것으로 판단된다.
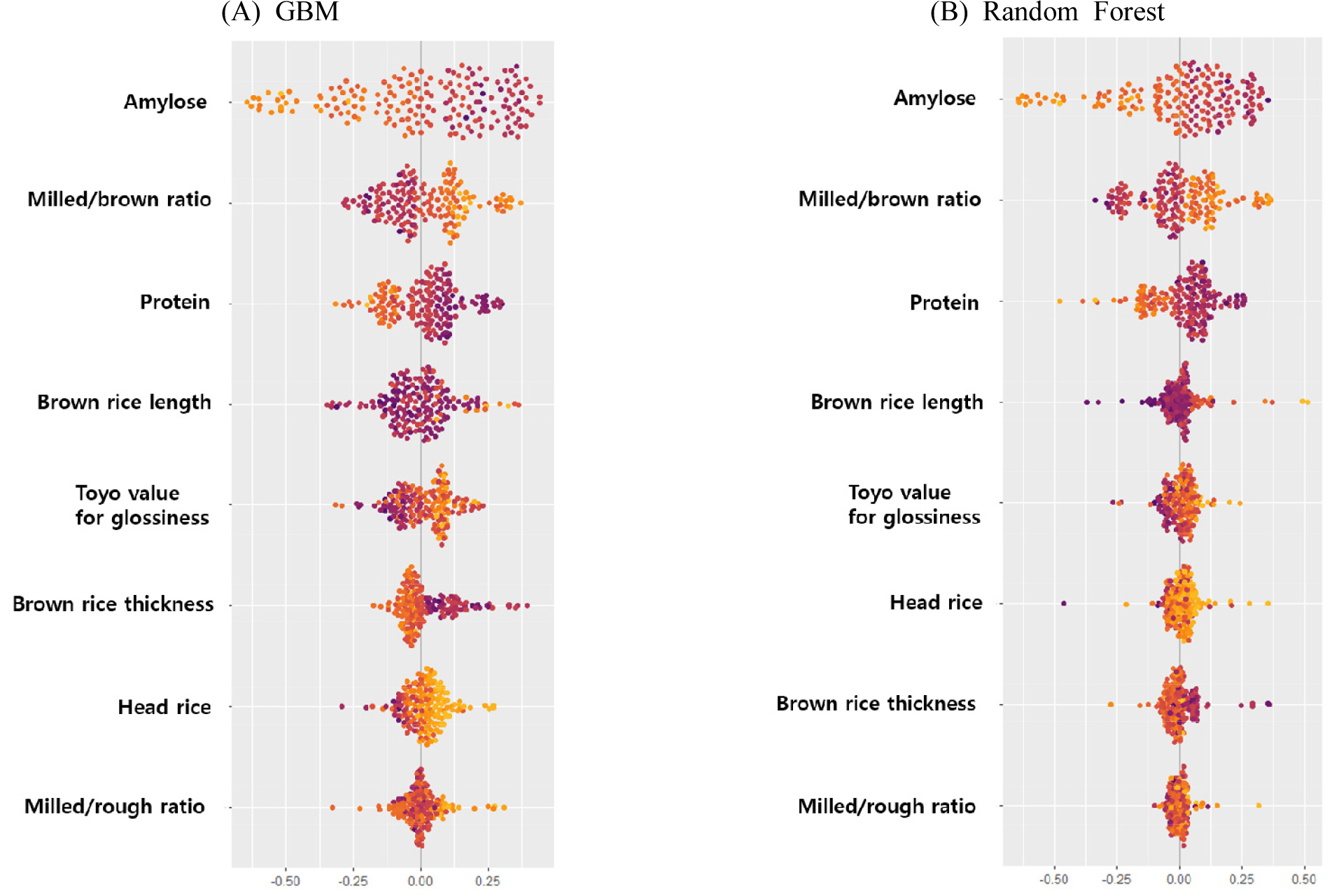
SHAP Value 분석 결과
본 연구에서는 A 클래스(우수)의 예측 확률을 기준으로 SHAP를 산출하여 각 예측변수가 밥맛 등급 분류(A/B)에 미치는 방향과 크기를 해석하였다. SHAP 값이 양수일수록 A로 분류될 가능성이 커지고, 음수일수록 B로 분류될 가능성이 작아진다(Lundberg et al., 2017; Bagheri, 2022). GBM과 Random Forest 모두에서 Amylose 함량, 현백율, 단백질 함량의 영향력이 컸다. 구체적으로 Amylose와 단백질 함량이 낮을수록 SHAP 값이 양의 방향으로 이동하여 A 분류 확률을 높였으며, 현백율은 증가할수록 SHAP 값이 양의 방향으로 이동하여 A 분류 확률을 높이는 것으로 나타나 낮은 Amylose·단백질과 높은 현백율이 우수한 밥맛 등급 예측에 기여하였다. 세부 분포는 SHAP summary plot에 제시하였다(Fig. 7). 또한, 주요 예측 변수인 Amylose와 단백질 간의 상호작용 효과를 탐색하기 위해 SHAP dependence plot을 분석하였다(Supplementary Fig. S4). 다만, 단백질 함량(색상)의 영향력이 일부 관찰되었으나, Amylose의 영향(x축)에 비해 지배적이지 않아 두 변수 간의 통계적으로 강한 상호작용은 확인되지 않았다.
선행연구와의 비교
본 연구의 SHAP 분석 결과는 선행 연구들과 일치한다. 여러 연구에서 Amylose 및 단백질 함량이 높을수록 밥맛이 저하되는 부의 상관이 일관되게 확인되었다(Gong et al., 2022; Liu et al., 2020; Youn & Kim, 2015; Cao et al., 2025). 본 연구에서 Amylose 및 단백질 증가가 A(우수) 확률 감소(음의 SHAP)라는 방향성은 위 선행 결과와 부합한다. 이러한 결과는 머신러닝을 활용한 품질 예측 시스템 개발에서 변수 선택의 타당성과 모델 해석 가능성을 높이는 한편, 밥맛에 영향을 주는 품질 특성에 대한 정보를 벼 품종 육종 연구에 제공함으로써 학문적·실용적 기여를 할 것으로 기대된다.
적 요
본 연구는 국립식량과학원에서 축적된 10여 년의 쌀 품질과 밥맛 기호도 데이터를 활용하여, 기호도 총평(A/B)의 예측 가능성과 해석 가능성을 갖춘 머신러닝 기반 평가체계를 제시하였다. 데이터 전처리 후 총 216개 시료를 대상으로 주성분분석(PCA), 군집분석 및 Preference Mapping을 통해 품질 특성의 구조를 파악하였으며, GBM (Gradient Boosting Machine)과 Random Forest 모델을 적용하여 밥맛 기호도 총평의 이진 분류(A/B)를 예측하였다. 모델의 일반화 성능은 교차검증과 독립 테스트세트로 평가하였고, 변수 중요도 해석에는 SHAP (Shapley Additive Explanations)을 활용하였다. 그 결과 Random Forest 모델이 GBM보다 높은 예측 정확도(Accuracy 0.7143)를 보였으며, Amylose, 단백질, 현백율이 밥맛 예측에 가장 큰 영향을 미쳤다.
이러한 결과는 (1) 감각검사의 비용·시간·주관성 한계를 보완할 수 있는 데이터 기반 보조도구의 가능성을 제시하고, (2) 육종·가공 단계에서 관리해야 할 핵심 지표(Amylose·단백질·현백율)를 정량적으로 제안한다는 점에서 학문적·실용적 의의가 있다. 다만 단일 기관 데이터와 이진 라벨 정의의 임계값 설정, 외부 코호트 검증의 부재는 한계로 남는다. 향후에는 다기관·다품종 확대, 외부/시계열 검증, 확장 지표(다등급 등), 그리고 현장 적용을 위한 경량화·캘리브레이션 절차의 표준화를 통해 모델의 보편성과 활용성을 한층 강화할 필요가 있다.
